Modèles scikit-learn¶
import platform
print(f"Python version: {platform.python_version()}")
assert platform.python_version_tuple() >= ("3", "6")
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import plotly
import plotly.graph_objs as go
import pandas as pd
import graphviz

Python version: 3.7.8
# Setup plots
%matplotlib inline
plt.rcParams["figure.figsize"] = 10, 8
%config InlineBackend.figure_format = "retina"
sns.set()
# Configure Plotly to be rendered inline in the notebook.
plotly.offline.init_notebook_mode()
import sklearn
print(f"scikit-learn version: {sklearn.__version__}")
assert sklearn.__version__ >= "0.20"
from scipy.special import softmax
from sklearn.model_selection import train_test_split
from sklearn.linear_model import (
LinearRegression,
LogisticRegression,
SGDRegressor,
Ridge,
SGDClassifier
)
from sklearn.model_selection import GridSearchCV
from sklearn.neural_network import MLPClassifier
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.tree import (
DecisionTreeClassifier,
DecisionTreeRegressor,
plot_tree,
export_graphviz
)
from sklearn.metrics import classification_report, mean_squared_error, plot_roc_curve
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
scikit-learn version: 0.23.2
Créer un modèle¶
from sklearn.datasets import make_moons, make_circles
x_train, y_train = make_moons(n_samples=1000, noise=0.10, random_state=0)
# Régression linéaire (Normal Equation)
model = LinearRegression()
# Régression Linéaire (Descente de gradient)
model = SGDRegressor()
# Régression logisitique (Descente de gradient)
model = SGDClassifier(loss="log") # log loss = binary crossentropy
# Softmax regression
model = LogisticRegression(multi_class="multinomial")
# --> s = softmax(scores)
# Decision tree classifier
model_tree = DecisionTreeClassifier(max_depth=2, random_state=42)
# Decision tree regression
model = DecisionTreeRegressor(max_depth=2)
# Random forest
model = RandomForestClassifier(n_estimators=200)
# Multilayer perceptron
model = MLPClassifier()
Entraîner le modèle¶
model.fit(x_train, y_train)
/opt/buildhome/python3.7/lib/python3.7/site-packages/sklearn/neural_network/_multilayer_perceptron.py:585: ConvergenceWarning:
Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet.
MLPClassifier()
# plot un decisiont tree
dot_data = export_graphviz(
model_tree,
out_file=None,
#feature_names=iris.feature_names[2:],
#class_names=iris.target_names,
filled=True,
rounded=True,
special_characters=True,
)
graphviz.Source(dot_data)
---------------------------------------------------------------------------
NotFittedError Traceback (most recent call last)
<ipython-input-7-5e1517ccce5d> in <module>
7 filled=True,
8 rounded=True,
----> 9 special_characters=True,
10 )
11 graphviz.Source(dot_data)
~/python3.7/lib/python3.7/site-packages/sklearn/utils/validation.py in inner_f(*args, **kwargs)
70 FutureWarning)
71 kwargs.update({k: arg for k, arg in zip(sig.parameters, args)})
---> 72 return f(**kwargs)
73 return inner_f
74
~/python3.7/lib/python3.7/site-packages/sklearn/tree/_export.py in export_graphviz(decision_tree, out_file, max_depth, feature_names, class_names, label, filled, leaves_parallel, impurity, node_ids, proportion, rotate, rounded, special_characters, precision)
762 """
763
--> 764 check_is_fitted(decision_tree)
765 own_file = False
766 return_string = False
~/python3.7/lib/python3.7/site-packages/sklearn/utils/validation.py in inner_f(*args, **kwargs)
70 FutureWarning)
71 kwargs.update({k: arg for k, arg in zip(sig.parameters, args)})
---> 72 return f(**kwargs)
73 return inner_f
74
~/python3.7/lib/python3.7/site-packages/sklearn/utils/validation.py in check_is_fitted(estimator, attributes, msg, all_or_any)
1017
1018 if not attrs:
-> 1019 raise NotFittedError(msg % {'name': type(estimator).__name__})
1020
1021
NotFittedError: This DecisionTreeClassifier instance is not fitted yet. Call 'fit' with appropriate arguments before using this estimator.
Il est bon ou pas ?¶
error = mean_squared_error(y_train, model.predict(x_train))
print(f"MSE: {error:.05f}")
accuracy = model.score(x_train, y_train)
print(f"Accuracy: {accuracy:.05f}")
MSE: 0.02900
Accuracy: 0.97100
Comparer¶
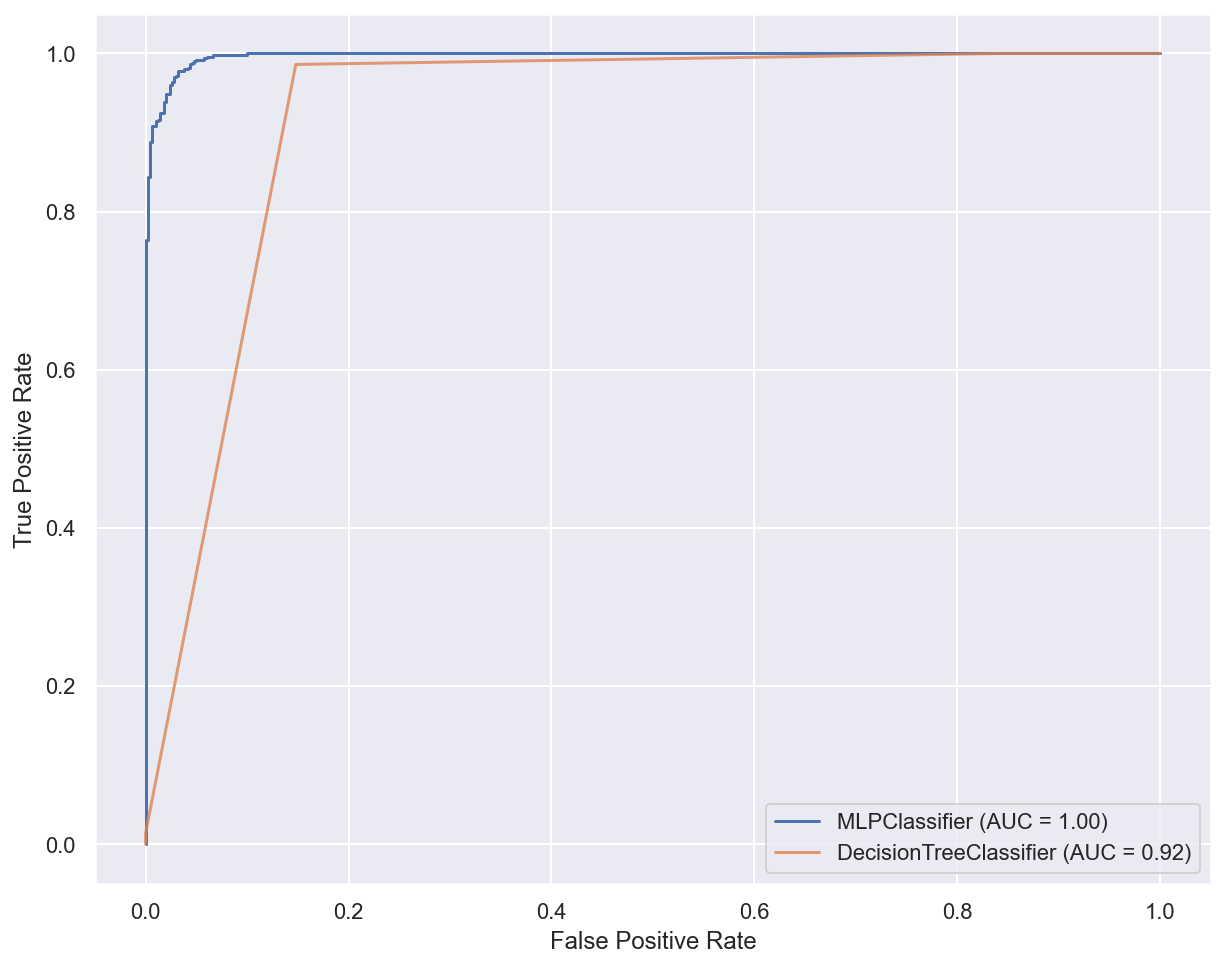
# Plot ROC curves for both classifiers
sgd_disp = plot_roc_curve(model, x_train, y_train)
ax = plt.gca()
rf_disp = plot_roc_curve(model_tree, x_train, y_train, ax=ax, alpha=0.8)
plt.show()
Tuner un modèle (Gridsearch)¶
# récupérer les paramètres
estimator = DecisionTreeClassifier()
estimator.get_params().keys()
parameters = [{'max_depth': np.arange(1, 21),
'min_samples_leaf': [1, 5, 10, 20, 50, 100]}]
grid_search_cv = GridSearchCV(estimator, parameters)
# Search for the best parameters with the specified classifier on training data
grid_search_cv.fit(x_train, y_train)
# Print the best combination of hyperparameters found
print(grid_search_cv.best_params_)
{'max_depth': 7, 'min_samples_leaf': 1}