Traitement des données¶
# Import base packages
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns

# Setup plots
%matplotlib inline
plt.rcParams['figure.figsize'] = 10, 8
%config InlineBackend.figure_format = 'retina'
sns.set()
# Import ML packages
import sklearn
print(f'scikit-learn version: {sklearn.__version__}')
from sklearn.datasets import load_breast_cancer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
scikit-learn version: 0.23.2
Un peu de safrané de numpy et pandas¶
# retirer des colonnes d'un dataframe (Pandas)
# df_iris.drop(columns=['target', 'class'])
Load some data¶
# sous macos le téléchargement de données provenant d'internet peut entrainer une erreur de vérification
# de certificat, ce bloc permet de contourner le problème en désactivant la vérification
import os, ssl
if (not os.environ.get('PYTHONHTTPSVERIFY', '') and getattr(ssl, '_create_unverified_context', None)):
ssl._create_default_https_context = ssl._create_unverified_context
csv_url = "https://raw.githubusercontent.com/bpesquet/mlkatas/master/_datasets/heart.csv"
df_heart = pd.read_csv(csv_url)
Exploration du jeu de données¶
# Afficher les informations du jeu de données
print(df_heart.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 301 entries, 0 to 300
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 age 301 non-null int64
1 sex 301 non-null int64
2 cp 301 non-null int64
3 trestbps 301 non-null int64
4 chol 301 non-null int64
5 fbs 301 non-null int64
6 restecg 301 non-null int64
7 thalach 301 non-null int64
8 exang 301 non-null int64
9 oldpeak 301 non-null float64
10 slope 301 non-null int64
11 ca 301 non-null int64
12 thal 301 non-null object
13 target 301 non-null int64
dtypes: float64(1), int64(12), object(1)
memory usage: 33.0+ KB
None
# Afficher 10 lignes au hasard
df_heart.sample(n=10)
| age | sex | cp | trestbps | chol | fbs | restecg | thalach | exang | oldpeak | slope | ca | thal | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 104 | 70 | 1 | 4 | 130 | 322 | 0 | 2 | 109 | 0 | 2.4 | 2 | 3 | normal | 0 |
| 150 | 64 | 0 | 3 | 140 | 313 | 0 | 0 | 133 | 0 | 0.2 | 1 | 0 | reversible | 0 |
| 125 | 56 | 1 | 4 | 132 | 184 | 0 | 2 | 105 | 1 | 2.1 | 2 | 1 | fixed | 0 |
| 77 | 44 | 1 | 2 | 120 | 220 | 0 | 0 | 170 | 0 | 0.0 | 1 | 0 | normal | 0 |
| 78 | 62 | 0 | 4 | 124 | 209 | 0 | 0 | 163 | 0 | 0.0 | 1 | 0 | normal | 0 |
| 279 | 46 | 1 | 3 | 150 | 231 | 0 | 0 | 147 | 0 | 3.6 | 2 | 0 | normal | 0 |
| 21 | 58 | 0 | 1 | 150 | 283 | 1 | 2 | 162 | 0 | 1.0 | 1 | 0 | normal | 0 |
| 33 | 59 | 1 | 4 | 135 | 234 | 0 | 0 | 161 | 0 | 0.5 | 2 | 0 | reversible | 0 |
| 170 | 53 | 1 | 4 | 123 | 282 | 0 | 0 | 95 | 1 | 2.0 | 2 | 2 | reversible | 1 |
| 210 | 44 | 1 | 3 | 120 | 226 | 0 | 0 | 169 | 0 | 0.0 | 1 | 0 | normal | 0 |
# Afficher les 10 premières lignes
df_heart.head(n=10)
| age | sex | cp | trestbps | chol | fbs | restecg | thalach | exang | oldpeak | slope | ca | thal | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 63 | 1 | 1 | 145 | 233 | 1 | 2 | 150 | 0 | 2.3 | 3 | 0 | fixed | 0 |
| 1 | 67 | 1 | 4 | 160 | 286 | 0 | 2 | 108 | 1 | 1.5 | 2 | 3 | normal | 1 |
| 2 | 67 | 1 | 4 | 120 | 229 | 0 | 2 | 129 | 1 | 2.6 | 2 | 2 | reversible | 0 |
| 3 | 37 | 1 | 3 | 130 | 250 | 0 | 0 | 187 | 0 | 3.5 | 3 | 0 | normal | 0 |
| 4 | 41 | 0 | 2 | 130 | 204 | 0 | 2 | 172 | 0 | 1.4 | 1 | 0 | normal | 0 |
| 5 | 56 | 1 | 2 | 120 | 236 | 0 | 0 | 178 | 0 | 0.8 | 1 | 0 | normal | 0 |
| 6 | 62 | 0 | 4 | 140 | 268 | 0 | 2 | 160 | 0 | 3.6 | 3 | 2 | normal | 1 |
| 7 | 57 | 0 | 4 | 120 | 354 | 0 | 0 | 163 | 1 | 0.6 | 1 | 0 | normal | 0 |
| 8 | 63 | 1 | 4 | 130 | 254 | 0 | 2 | 147 | 0 | 1.4 | 2 | 1 | reversible | 1 |
| 9 | 53 | 1 | 4 | 140 | 203 | 1 | 2 | 155 | 1 | 3.1 | 3 | 0 | reversible | 0 |
# Afficher les statistiques descriptives des variables numériques
df_heart.describe()
| age | sex | cp | trestbps | chol | fbs | restecg | thalach | exang | oldpeak | slope | ca | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 301.000000 | 301.000000 | 301.000000 | 301.000000 | 301.000000 | 301.000000 | 301.000000 | 301.000000 | 301.000000 | 301.000000 | 301.000000 | 301.000000 | 301.000000 |
| mean | 54.571429 | 0.677741 | 3.126246 | 131.684385 | 246.817276 | 0.146179 | 0.996678 | 149.308970 | 0.328904 | 1.061462 | 1.594684 | 0.677741 | 0.275748 |
| std | 9.041702 | 0.468120 | 1.008634 | 17.709415 | 52.186619 | 0.353874 | 0.988259 | 22.953015 | 0.470597 | 1.167295 | 0.617931 | 0.937623 | 0.447634 |
| min | 29.000000 | 0.000000 | 0.000000 | 94.000000 | 126.000000 | 0.000000 | 0.000000 | 71.000000 | 0.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 |
| 25% | 48.000000 | 0.000000 | 3.000000 | 120.000000 | 211.000000 | 0.000000 | 0.000000 | 132.000000 | 0.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 |
| 50% | 56.000000 | 1.000000 | 3.000000 | 130.000000 | 242.000000 | 0.000000 | 1.000000 | 152.000000 | 0.000000 | 0.800000 | 2.000000 | 0.000000 | 0.000000 |
| 75% | 61.000000 | 1.000000 | 4.000000 | 140.000000 | 275.000000 | 0.000000 | 2.000000 | 165.000000 | 1.000000 | 1.600000 | 2.000000 | 1.000000 | 1.000000 |
| max | 77.000000 | 1.000000 | 4.000000 | 200.000000 | 564.000000 | 1.000000 | 2.000000 | 202.000000 | 1.000000 | 6.200000 | 3.000000 | 3.000000 | 1.000000 |
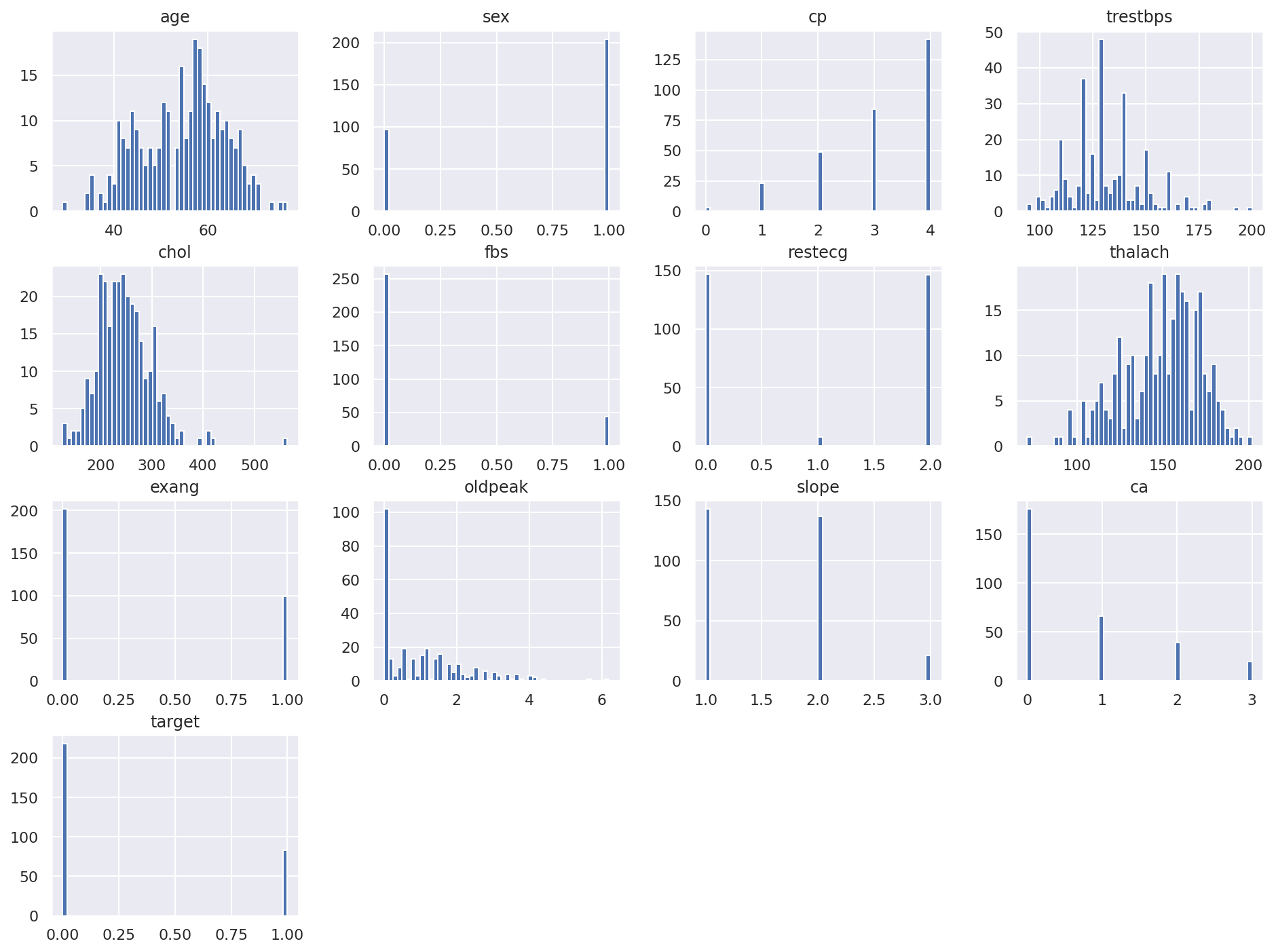
# Afficher la distribution des variables
df_heart.hist(bins=50, figsize=(16, 12))
plt.show()
Variables qualitatives et quantitatives¶
# Récupérer les variables numériques
num_features = df_heart.select_dtypes(include=[np.number]).columns
# Récupérer les variables catégorielles (quali)
cat_features = df_heart.select_dtypes(include=[np.object]).columns
# Afficher les valeurs pour une variables donnée
df_heart["thal"].value_counts()
normal 168
reversible 115
fixed 18
Name: thal, dtype: int64
df_heart['thal'].astype('category').cat.categories
Index(['fixed', 'normal', 'reversible'], dtype='object')
Préparation du jeu de données¶
# Diviser le jeu de données (automatique)
df_train, df_test = train_test_split(df_heart, test_size=0.2)
# Diviser le jeu de données (manuel)
x = df_heart.iloc[:, 0:13].to_numpy()
y = df_heart.iloc[:, 13].to_numpy()
# Shuffle le jeu de données
permutations = np.random.permutation(len(df_train))
x_permut = x[permutations, :]
y_permut = y[permutations]
# diviser en test/train/val
prcTest = 0.25
prcVal = 0.2
x_test = x_permut[0:int(prcTest*len(x)),:]
x_train = x_permut[int(prcTest*len(x)):,:]
x_val = x_train[0:int(prcVal*len(x)),:]
x_train = x_permut[int(prcVal*len(x)):,:]
# Conversion en one hot
enc = OneHotEncoder(handle_unknown='ignore')
one_hot = pd.DataFrame(enc.fit_transform(df_heart[['thal']]).toarray())
new_df = df_heart.join(one_hot)
new_df.drop(columns=['thal'])
| age | sex | cp | trestbps | chol | fbs | restecg | thalach | exang | oldpeak | slope | ca | target | 0 | 1 | 2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 63 | 1 | 1 | 145 | 233 | 1 | 2 | 150 | 0 | 2.3 | 3 | 0 | 0 | 1.0 | 0.0 | 0.0 |
| 1 | 67 | 1 | 4 | 160 | 286 | 0 | 2 | 108 | 1 | 1.5 | 2 | 3 | 1 | 0.0 | 1.0 | 0.0 |
| 2 | 67 | 1 | 4 | 120 | 229 | 0 | 2 | 129 | 1 | 2.6 | 2 | 2 | 0 | 0.0 | 0.0 | 1.0 |
| 3 | 37 | 1 | 3 | 130 | 250 | 0 | 0 | 187 | 0 | 3.5 | 3 | 0 | 0 | 0.0 | 1.0 | 0.0 |
| 4 | 41 | 0 | 2 | 130 | 204 | 0 | 2 | 172 | 0 | 1.4 | 1 | 0 | 0 | 0.0 | 1.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 296 | 52 | 1 | 1 | 118 | 186 | 0 | 2 | 190 | 0 | 0.0 | 2 | 0 | 0 | 1.0 | 0.0 | 0.0 |
| 297 | 43 | 0 | 4 | 132 | 341 | 1 | 2 | 136 | 1 | 3.0 | 2 | 0 | 1 | 0.0 | 0.0 | 1.0 |
| 298 | 65 | 1 | 4 | 135 | 254 | 0 | 2 | 127 | 0 | 2.8 | 2 | 1 | 1 | 0.0 | 0.0 | 1.0 |
| 299 | 48 | 1 | 4 | 130 | 256 | 1 | 2 | 150 | 1 | 0.0 | 1 | 2 | 1 | 0.0 | 0.0 | 1.0 |
| 300 | 63 | 0 | 4 | 150 | 407 | 0 | 2 | 154 | 0 | 4.0 | 2 | 3 | 1 | 0.0 | 0.0 | 1.0 |
301 rows × 16 columns
# Normalisation (centrer - réduire)
scaler = StandardScaler().fit(new_df)
x_normalized = scaler.transform(new_df)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-17-544e8faab64a> in <module>
1 # Normalisation (centrer - réduire)
----> 2 scaler = StandardScaler().fit(new_df)
3 x_normalized = scaler.transform(new_df)
~/python3.7/lib/python3.7/site-packages/sklearn/preprocessing/_data.py in fit(self, X, y)
665 # Reset internal state before fitting
666 self._reset()
--> 667 return self.partial_fit(X, y)
668
669 def partial_fit(self, X, y=None):
~/python3.7/lib/python3.7/site-packages/sklearn/preprocessing/_data.py in partial_fit(self, X, y)
696 X = self._validate_data(X, accept_sparse=('csr', 'csc'),
697 estimator=self, dtype=FLOAT_DTYPES,
--> 698 force_all_finite='allow-nan')
699
700 # Even in the case of `with_mean=False`, we update the mean anyway
~/python3.7/lib/python3.7/site-packages/sklearn/base.py in _validate_data(self, X, y, reset, validate_separately, **check_params)
418 f"requires y to be passed, but the target y is None."
419 )
--> 420 X = check_array(X, **check_params)
421 out = X
422 else:
~/python3.7/lib/python3.7/site-packages/sklearn/utils/validation.py in inner_f(*args, **kwargs)
70 FutureWarning)
71 kwargs.update({k: arg for k, arg in zip(sig.parameters, args)})
---> 72 return f(**kwargs)
73 return inner_f
74
~/python3.7/lib/python3.7/site-packages/sklearn/utils/validation.py in check_array(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator)
596 array = array.astype(dtype, casting="unsafe", copy=False)
597 else:
--> 598 array = np.asarray(array, order=order, dtype=dtype)
599 except ComplexWarning:
600 raise ValueError("Complex data not supported\n"
~/python3.7/lib/python3.7/site-packages/numpy/core/_asarray.py in asarray(a, dtype, order)
83
84 """
---> 85 return array(a, dtype, copy=False, order=order)
86
87
~/python3.7/lib/python3.7/site-packages/pandas/core/generic.py in __array__(self, dtype)
1779
1780 def __array__(self, dtype=None) -> np.ndarray:
-> 1781 return np.asarray(self._values, dtype=dtype)
1782
1783 def __array_wrap__(self, result, context=None):
~/python3.7/lib/python3.7/site-packages/numpy/core/_asarray.py in asarray(a, dtype, order)
83
84 """
---> 85 return array(a, dtype, copy=False, order=order)
86
87
ValueError: could not convert string to float: 'fixed'
### Pipeline de traitement
# Utilisation de Pipeline pour préparer les données
num_pipeline = Pipeline(
[("imputer", SimpleImputer(strategy="median")), # remplace les valeurs manquantes
("std_scaler", StandardScaler()),] # normalisation des données (centré-réduit)
)
full_pipeline = ColumnTransformer(
[("num", num_pipeline, num_features), # on applique le pipeline sur les variables numériques
("cat", OneHotEncoder(), cat_features),] # on encode les variables quanti en one hot
)
# On applique le pipeline sur les données d'entrainement
x_train = full_pipeline.fit_transform(df_train)